 在线客服
在线客服 
您现在的位置:计算机毕业设计源码网 > 热门毕业设计 > 基于随机森林算法的空气质量预测系统研究
精品推荐







程序效果图

- 程序信息
- ID编号:3609
- 编码:GBK及UTF-8
- 浏览量:
- 适用站点:Python毕业设计
- 最后更新:2026-01-19 09:41
程序架构描述:
近年来,我国大气污染较为严重,许多区域的空气质量时不时的亮起红灯,不但影响人们的出行,还会给人们的生命财产造成严重的威胁。造成大气污染的因素较多,既有自然因素,也有人为因素造成,其中最为主要的原因是人们对煤炭、工业、汽车等过度依赖等造成的。调整城市工业的产业结构,减少污染气体的排放是城市应对大气污染的主要策略,而如何找出工业中的污染源,及时进行处理称为环保部门最为关心的问题。随着人工智能技术的发展,通过大数据技术从气象部门检测的大气污染物的含量数据中挖掘有价值的数据,对空气质量分提前预测,可帮助环保部门预判污染气体排放源有着重要的帮助,同时人们可根据空气质量情况合理安排日常出行,减少污染气体给人们的身体健康造成伤害。在此背景下选择基于随机森林算法的空气质量预测课题进行研究很有必要。
本文对2022年成都空气质量情况进行研究,采用多分类随机森林模型算法,建立城市空气质量分类随机森林模型。本文主要实现:(1)通过天气后报等平台采集2022年成都空气质量数据,并进行城市空气质量数据缺失值统计,采用均值查补法完善数据,对其空气质量数据进行数字化处理。(2)绘制PM2.5、PM10等城市空气质量数据变量与空气质量之间散点图,分析城市空气质量数据的相关性;对城市空气质量数据的离散度进行分析,对离散值进行剔除;对城市空气质量进行统计分析,分析每月空气质量优、良污染等出现天数,统计各空气质量类别下发生的天数。(3)通过python语言中的随机森林算法实现城市空气质量分类随机森林模型,生成城市空气质量分类随机森林并可视化显示,通过城市空气质量分类随机森林模型分类报告中精确度、召回率、F1值数据对该模型进行评估,观察该模型的混淆矩阵、ROC曲线评估城市空气质量分类器的效果,分别通过城市空气质量测试集以及输入数据进行预测。通过分析该模型的重要特征评估报告,得出Co、SO2、NO2的浓度对空气质量影响最大。通过实验数据验证,该城市空气质量分类随机森林模型准确度为93.53%,它能够提供准确的空气质量预报结果为人们出行和环保部门判断污染源提供决策。
关键词:空气质量预测;Co;随机森林算法;F1值
研究的背景及意义
研究背景
近年来,我国的大气环境呈现多样化的状态,出现烟煤型污染与氧化性污染共同存在、局部地区污染和大片区域污染等各种情况叠加的现象,发生了不同污染物相互之间融合反应生成新污染的情况[1]。现如今主要以雾霾天气为代表的复合型污染严重的影响人们的身体健康,人们对城市的光化学烟雾引起的大气污染特别的关注。国家对大气污染也特别重视,将每个城市的空气质量纳入城市综合评比项,并发布各个城市对空气质量至少日报的政策。2021年习主席强调将减少碳排放、提高空气质量作为环境治理的主要任务。如何精准预判空气质量,对污染区域进行专项治理是环境治理部门迫切关注的问题[2]。基于此大背景下,以气象部门检测的大气污染物的含量为依据,建立空气质量的预测模型,实现对城市区域的空气质量提前预判,从而提高空气质量的气象服务,协助环境部门对研判污染物的排放以及空气质量变化情况都有重要的决策在指导,因此本文选择基于随机森林算法的空气质量预测作为研究课题。
研究目的意义
随着社会经济的发展,促进人们的生活水平逐渐提高,人们对生活环境的空气质量情况也逐渐的关注起来,空气质量的好坏直接与人们的出行也息息相关,遇到空气质量差尤其出现雾霾天气,对于计划出行的人们影响非常大,另外良好的空气质量有益于人们的身体健康,因此上至国家政府下至人民群众对与空气质量情况格外关注,由此空气中污染物等信息数据为样本,随机森林对城市空气质量进行预测有着重要的研究价值。
(1)人们提前掌握空气质量情况,可以根据需要合理的安排自己的出行计划,防止因雾霾天气等原因造成出行计划搁置,同时在良好的空气质量环境中出行,能够保护自身的健康,减少各种疾病的发病率,同时可时刻提醒人们,保护环境,减少污染从自我做起。
(2)大气污染对环境有很大的危害,而环境是社会经济发展的前提,因为一些污染环境的经济发展结构和模式最终会产生不良的社会效应,对于社会经济可持续发生起到阻碍作用,因此提前掌握空气质量情况,对于污染性企业的关停限产工作有着指导意义,
(3)空气质量预测对于环保部门,通过提前弄清楚空气污染情况,采取有效的措施遏制污染物,提高空气质量,同时也相应国家政策,坚持对城市的空气质量每日进行预报。
国内外研究现状
我国经济的飞速发展,导致大气污染的问题越发严重,空气质量严重下降,影响人们的身心健康,国家对于空气质量分析研究工作格外重视,许多专家就空气质量的预测分析进行了专门的研究。2019年,夏润,张晓龙通过改进集成学习算法对空气质量进行预测,他们研究的核心是改进OPGBoost算法,为了能够得到更多有效的空气质量相关数据信息,采用Boruta算法对空气质量数据特征进行筛选,最后通过创建OPGBoost组合模型,对空气质量和PM2.5的浓度进行预测,通过实验数据的验证,发展该OPGBoost组合模型的准确性和实用性都是非常强的[3]。张旭通过神经网络算法对空气质量进行预测,他们为了提高对PM2.5等污染物浓度预测度,除了考虑其他污染物得浓度外,将气象因素也考虑进来,并且通过BP神经网络以及深度置信网络建立PM2.5的预测模型。另外为了对小时数据的PM2.5的浓度进行预测,由于小时数据非常庞大,通过建立DBN-SVR预测模型来预测[4]。张晗主要对基于LSTM神经网络实现了空气污染监测预报系统,他指出为了提前了解空气污染情况,指定合理的污染遏制措施,建立空气污染监测预报系统很有必要,他主要依据空气污染和气象数据的时间特点,从时间角度建立他们的关联性,构建LSTM神经网络的空气质量预测模型[5]。
2020年,荆海航等人基于时空数据建立空气质量预测模型,她重点分析空气质量的时空影响因素,利用空间估值划分的方法,获取与该空间区域相关的其他区域的空气质量因素信息,建立关联关系,基于ASTPN模型和ARIMA模型方法,构建空气质量预测模型,对每天24小时的空气质量情况进行预测[6]。刘星宇使用机器学习方法进行空气质量分析和预测,同样深入讨论污染物浓度和气象因素之间的关系,基于ARIMA-SVM模型对空气中的PM2.5的浓进行预测,为了得到高质量的气象因素与污染物浓度的相关数据,他采用K-means聚类算法对数据中的异常值进行处理,其重要是将污染物浓度作为标签,通过聚类中心将气象因素进行聚类,对于异常的气象因素数据分类删除[7]。
2021年,门瑞基于多维特征深度融合的技术对空气质量预测方面的内容进行研究,他依据国家环境监测中心全球预报系统的数据,主要从空间、时间、时空等角度来研究与空气质量有关的因子,基于多空间、时间等相互影响的思想达到降低预测偏差的目的,使得空气质量的预测结果更加贴近实际[8]。祁柏林,郭昆鹏,杨彬等人基于GCN-LSTM技术对空气质量预测进行研究,他们先通过GCN网络分析各个空间检测点的之间的空间关系,接着通过LSTM来得到空间检测的时间特征,最后通过线性回归的方法将得到的空间和时间特征相结合来预测空气质量[9]。通过实验数据验证表明,这种空间和时间结合的方法建立LSTM空气质量预测模型比单一的LSTM空气质量预测模型效果要好很多。王旭坪,于秀丽等人基于集成学习策略方法,主要对化工园区大气污染影响预测进行研究,他们通过对比各种机器学习的预测模型,发现将各种机器学习方法结合得到的化工园区大气污染影响预测模型要比单一的预测模型要好,无论是从模型精度还是从模型的泛化性方面都较为优秀,通过建园区大气污染影响预测模型分析发现,在相同的园区,不同的企业对污染物以及不同的排放口对空气的污染程度也是不同,因此政府可根据大气污染影响预测针对不同的企业进行因地制宜,建立合理的污染管控制度[10]。
国外,工业的发展使得全球的大气污染更加严重,空气质量问题也是全球关注的问题,许多外国学者就空气质量相关工作做了研究。2019年,Esatbeyoglu Enes,Sass Andreas等人基于移动测量数据对空气质量进行预测,本次实验它们通过车辆安装测量技术,对移动路线对应的空气中的NO2浓度等数据进行测量,将测试的NO2浓度等数据作为影响空气质量的因素,进行预测空气质量[11]。Vairo T.,Lecca M.,Trovatore E.等人基于贝叶斯网络对本地的空气质量建模预测,提前预报空气质量,其预测的目标是根据特定区域停滞的污染物情况进行预测空气质量,他们选择意大利的热那亚的空气污染物的相关数据为研究对象[12]。K Srinivasa Rao,G. Lavanya Devi,N. Ramesh]等人采用LSTM递归神经网络技术对维沙卡帕特南的空气质量进行预测,他们通过提取维沙卡帕特南的空气中的NO2浓度等数据,分析不同时间空气中NO2浓度、PM2.5等数据走势,并建立模型预测空气质量[13。Afsaneh Ghasemi,Jamil Amanollahi等人对空气质量预报ANFIS模型和选择方法集成课题进行研究,他们通过分析指出与空气质量相关的因子主要以污染物的浓度以及区域的相对湿度、温度、降水、压力等气象因素也有一定的关系,因此将这些数据作为因子,采用FS方法和ANFIS模型进行空气质量的预测[14]。
2020年,Chadha A.,Gupta S.等人基于机器学习算法对空气质量预测,他们指出空气污染不但对人们的健康有一定的威胁,而且对环境有一定的危害,因此对于空气质量的预测很有必要,他们以印度城市的空气质量指数为预测对象,采用时间序列模型预测造成空气污染的每个污染物的浓度,然后基于这些污染物的浓度,采用回归模型预测空气质量指数[15]。Saini Jagriti,Dutta Maitreyee等人基于SGD优化器对室内的空气质量进行预测,他们对印度农村室内空气环境进行调研,发现印度农村室内使用的煤油、木柴、沼气等等都是降低室内空气质量的主要原因,每年死于室内空气质量差的人数有1万人,基于此种情况,他们通过SGD优化器方法对室内的空气质量进行预测,提前预报室内空气质量,有助于印度民众做好防护工作[16]。
研究内容及章节安排
本文以2022年成都市气象部门检测的空气质量数据为研究对象,建立城市空气质量分类随机森林模型对未来空气质量进行预报。其组织结构如下。
第一章绪论,重点分析我国大气污染的现状以及空气质量预报的重要性,对国内外大气污染相关研究情况进行介绍,同时阐述了随机森林算法在其它领域的应用情况,最后得出本文以空气质量预测为研究内容,并对本文结构做了阐述。
第二章重要算法及相关技术介绍,重点阐述了随机森林分类算法以及评估的相关知识。
第三章市空气质量数据准备和清洗,主要围绕城市空气质量数据来源、相关因素确定、采集、城市空气质量数据清洗等内容展开描述。
第四章城市空气质量数据分析,重点叙述了城市空气质量数据相关性分析、城市空气质量数据离散度分析处理以及城市空气质量统计分析等内容。
第五章城市空气质量分类随机森林模型构建,主要介绍了城市空气质量分类随机森林模型从训练、到评估预测的相关过程。
第六章总结与展望,对基于随机森林算法的空气质量预测课题的研究做以总结,对下步该课题延申的内容进行阐述
城市空气质量数据转换
成都的空气质量数据包含了多个指标,如空气质量等级(以文字形式表示)、PM2.5、PM10、SO2、CO、NO2和O3的浓度值(以字符形式表示,包含单位μg/m³或mg/m³)。为了进行进一步的数据分析或可视化,我们需要对这些数据进行转换。
一、转换步骤:
(1)空气质量等级转换:
空气质量等级包含优、良、轻度污染、中度污染、重度污染、严重污染六个等级。
我们需要将这些等级转换为数字形式,其中“优”对应0,“良”对应1,“轻度污染”对应2,依此类推,直到“严重污染”对应5。
(2)污染物浓度值转换:
对于PM2.5、PM10、SO2、CO、NO2和O3的浓度值,我们需要去掉其单位(μg/m³或mg/m³),并将剩余的字符转换为数字形式。。
(3)数据存储:
转换后的数据将被保存到一个名为“成都空气质量类型数据.xls”的Excel文件中。
这个文件将包含转换后的空气质量等级和污染物浓度值。
二、具体操作:
(1)读取原始数据:
首先,我们需要读取存储成都空气质量数据的原始文件或数据源。
(2)空气质量等级转换:
使用条件语句(如if-else)来实现空气质量等级的转换。遍历数据集中的空气质量等级字段,并根据等级将其转换为对应的数字。
(3)污染物浓度值转换:
使用字符串处理函数(如Python中的str.replace())来去除浓度值中的单位。使用类型转换函数(如Python中的int()或float())将剩余的字符转换为数字。
(4)数据存储:使用数据处理库pandas和Excel写入库openpyxl来创建和写入Excel文件。将转换后的数据存储在“成都空气质量类型数据.xls”文件中,确保文件的格式和列名正确。
城市空气质量数据去重
根据采集的目的值采集2022年全年每日的数据,根据采集结果得到369条数据,通过统计本城市空气质量数据的重复数据共计1条,因此通过df的drop_duplicates()的方法对城市空气质量数据进行去重,将得到的结果存储在文件“成都空气质量去重数据.xls”中。
城市空气质量数据相关性分析
本节对PM2.5、PM10、SO2、CO、NO2、O3数据与空气质量关联关系进行分析,确认那些数据会影响空气质量,那些对空气质量的影响大,那些对空气质量影响较小。分别通过各个属性与空气质量的散点图和pearson系数进行分析
PM2.5与空气质量相关性分析
从成都市空气质量数据表中读取PM2.5的数据以及空气质量数据,将其绘制成散点图如下:

经过对数据的观察和分析,我们发现PM2.5的浓度与空气质量之间存在显著的关联性。具体而言,随着PM2.5浓度的增加,空气质量的数值也相应增大,即空气质量逐渐恶化。具体来说,当PM2.5浓度低于50μg/m³时,空气质量多数表现为“优”;在50至100μg/m³之间时,空气质量多呈现为“良”;而当PM2.5浓度超过100μg/m³后,空气质量开始迅速下降,从“轻度污染”逐渐发展到“严重污染”,尤其是当PM2.5浓度超过200μg/m³时,空气质量均为“严重污染”。
为了量化这种关联性,我们计算了PM2.5浓度与空气质量之间的Pearson相关系数,得到的值为0.93085592207750。这个值非常接近1,根据Pearson相关系数的规则,这意味着PM2.5浓度与空气质量之间存在极强的正相关关系。换句话说,PM2.5浓度的变化几乎可以完全解释空气质量的变化。
结合PM2.5与空气质量的散点图以及Pearson相关系数,我们可以确信PM2.5是影响空气质量的关键因素之一。不仅如此,PM2.5对空气质量的影响还是正向的,即PM2.5浓度的增加会导致空气质量的恶化。这一发现对于理解和管理空气污染问题具有重要的实际意义,提示我们在制定环保政策、改善空气质量时需要特别关注PM2.5的排放和控制。
PM10与空气质量相关性分析
从成都市空气质量数据表中读取PM10的数据以及空气质量数据,将其绘制成散点图如下:

经过对数据的细致分析,我们发现PM10的浓度与空气质量之间存在密切的关联性。具体来说,随着PM10浓度的增加,空气质量的数值也相应增大,即空气质量逐渐变差。当PM10浓度低于60μg/m³时,空气质量多数表现为“优”;在60至110μg/m³之间时,空气质量多呈现为“良”;而当PM10浓度超过140μg/m³后,空气质量开始迅速下降,从“轻度污染”逐渐发展到“严重污染”,尤其是当PM10浓度超过200μg/m³时,空气质量多为“严重污染”。为了量化这种关联性,我们计算了PM10浓度与空气质量之间的Pearson相关系数,得到的值为0.91741514434416。这个值非常接近1,根据Pearson相关系数的规则,这意味着PM10浓度与空气质量之间存在极强的正相关关系。换句话说,PM10浓度的变化几乎可以完全解释空气质量的变化。
结合PM10与空气质量的散点图以及Pearson相关系数,我们可以确信PM10是影响空气质量的关键因素之一。不仅如此,PM10对空气质量的影响是正向的,即PM10浓度的增加会导致空气质量的恶化。这一发现对于理解和管理空气污染问题具有重要的实际意义,提示我们在制定环保政策、改善空气质量时需要特别关注PM10的排放和控制。
SO2与空气质量相关性分析
从成都市空气质量数据表中读取SO2的数据以及空气质量数据,将其绘制成散点图如下:

通过观察该图,发现随着SO2的值增加,空气质量的数字越大,当SO2小于6以内,空气质量呈现优的居多,当SO2在3到9以内空气质量呈现良的居多,当SO2超过9开始,空气质量从轻度污染一直飙升到严重污染。其中超过12的基本是严重污染。
计算SO2与空气质量之间的pearson系数,得到的值是0.937062627625595,该系数值非常大,根据pearson值规则,当越靠近1的情况下,反应SO2与空气质量紧密度很好。同时本值为整数,说明它对空气质量正向影响。
结合SO2与空气质量散点图与其pearson系数最终可得出,SO2的关联性很强,而且对空气质量产生正影响。
CO与空气质量相关性分析
从成都市空气质量数据表中读取CO的数据以及空气质量数据,将其绘制成散点图如下:

经过对数据的详细分析,我们发现CO的浓度与空气质量之间存在一定程度的关联性。具体来说,随着CO浓度的增加,空气质量的数值也相应增大,即空气质量逐渐变差。当CO浓度为0时,空气质量多数表现为“优”或“良”。然而,当CO浓度增加到1mg/m³时,空气质量多数呈现为“污染”。当CO浓度超过1mg/m³后,空气质量开始迅速下降,从“轻度污染”逐渐发展到“严重污染”,特别是当CO浓度超过2mg/m³时,空气质量多为“严重污染”。
为了量化这种关联性,我们计算了CO浓度与空气质量之间的Pearson相关系数,得到的值为0.7044382539902698。这个值虽然不是非常高,但也表明两者之间存在一定程度的正相关关系。根据Pearson相关系数的规则,这个值意味着CO浓度与空气质量之间有一定的紧密度,但并非非常强。
结合CO与空气质量的散点图以及Pearson相关系数,我们可以得出结论:CO的关联性一般,但它对空气质量确实产生了正向影响。这一发现对于理解和管理空气污染问题具有一定意义,提示我们在制定环保政策、改善空气质量时需要关注CO的排放和控制。然而,与PM2.5、PM10和NO2等其他污染物相比,CO与空气质量的关联性可能较弱,这可能是由于多种因素的综合影响所致。
城市空气质量数据离散度分析
本节对PM2.5、PM10、SO2、CO、NO2、O3数据的离散度进行分析,确认各个属性数值中不能存在离群的数据,如果离群则严重影响预测结果。
PM2.5数据异常值分析
从成都市空气质量数据表中读取PM2.5的数据,将其绘制成箱型图观察其离散度,其图如下图

从图可知,PM2.5值的范围:PM2.5的上边缘值(最大值或第三四分位数与1.5倍四分位距之差)是180,而下边缘值(最小值或第一四分位数减去1.5倍四分位距)是4。这个范围表明PM2.5值的上下区间跨度确实较大。
四分位数信息:PM2.5值的上四分位数(Q3)是60,这表示有75%的PM2.5值低于或等于60。下四分位数(Q1)是25,意味着有25%的PM2.5值低于或等于25。中位数(Q2)是40,它位于数据的中间位置,说明有一半的PM2.5值高于40,而另一半低于40。
数据分布:根据四分位数和中位数,我们可以看出PM2.5值大多数情况下分布在25到60的区间内,特别是中位数40附近的区间,这表明大多数观测值聚集在这个范围内。
离群值:箱型图中最顶部接近300的位置存在离散的PM2.5值,这些点被认为是离群值或极端值,因为它们远离了数据的主要分布区域。在数据分析中,离群值可能会对数据解释和模型构建产生不利影响。
剔除边界:基于经验或特定应用场景,您建议将PM2.5值的剔除边界设置为200。这意味着在进一步的数据分析或模型构建中,您可能会选择忽略或特殊处理那些大于200的PM2.5值。然而,是否剔除离群值取决于分析的目的和上下文。在某些情况下,保留离群值可能更重要,因为它们可能包含有价值的信息。
城市空气质量统计分析
本节主要对城市空气质量情况按照每月统计分析和按照空气质量按类别统计分析,观察在成都市2022年各种空气质量的情况。
每月空气质量统计分析
按照月份统计2022年每个月优、良、轻度污染、中度污染、重度污染、严重污染分别对应的天气个数,得到的每月空气质量统计柱状图如下。

通过观察每月空气质量统计柱状图,分别得出以下的统计数量:
(1)一月份的优、良、轻度污染、中度污染、重度污染、严重污染的统计天数分别对应8、16、15、1、0、1。通过结果可以看出,本月以轻度污染为主流天气,以优、良天气次之。
(2)二月份的优、良、轻度污染、中度污染、重度污染、严重污染的统计天数分别对应12、14、0、1、1、0。通过结果可以看出,本月的天气质量优和良较多,不存在污染非常严重的天数,整体空气质量良好。
(3)三月份的优、良、轻度污染、中度污染、重度污染、严重污染的统计天数分别对应8、19、4、0、0、0。通过结果可以看出,本月良天气占据多数,轻度污染出现少量,整体空气质量良好。
(4)四月份的优、良、轻度污染、中度污染、重度污染、严重污染的统计天数分别对应12、18、0、0、0、0;五月份的优、良、轻度污染、中度污染、重度污染、严重污染的统计天数分别对应21、10、0、0、0、0,本月空气质量优占据大多数;六月份的优、良、轻度污染、中度污染、重度污染、严重污染的统计天数分别对应17、13、0、0、0、0,本月的优良天气相当;七月份的优、良、轻度污染、中度污染、重度污染、严重污染的统计天数分别对应15、16、0、0、0、0,本月的优良天气相当;八月份的优、良、轻度污染、中度污染、重度污染、严重污染的统计天数分别对应17、14、0、0、0、0本月的优良天气相当;通过观察这5个月的天气治理效果不错,没有污染天气存在。
(5)九月份的优、良、轻度污染、中度污染、重度污染、严重污染的统计天数分别对应16、5、0、3、6、0。通过结果可以看出,本月的天气质量整体不好,其轻度污染和重度污染占据本月将近1/3的天数。
(6)十月份的优、良、轻度污染、中度污染、重度污染、严重污染的统计天数分别对应5、17、5、2、2、0。通过结果可以看出,本月的天气质量整体不好,其轻度污染、中度污染和重度污染都出现好几天,大多数空气质量呈现良好状态。
(7)十一月份的优、良、轻度污染、中度污染、重度污染、严重污染的统计天数分别对应1、13、5、3、5、3。通过结果可以看出,本月的天气质量整体不好,其轻度污染、中度污染和重度污染、严重污染都出现好几天,本月空气质量比较糟糕。
(8)十二月份的优、良、轻度污染、中度污染、重度污染、严重污染的统计天数分别对应1、21、4、3、5、1。本月的天气质量整体不好,其轻度污染、中度污染和重度污染、严重污染都出现好几天,本月空气质量比较糟糕。
从整体进行分析,这一年九月到二十月的空气质量比较糟糕,其它月份相对较好。
城市空气质量分类随机森林模型构建
空气质量分类随机森林模型训练
(1)数据集:
在构建预测空气质量情况的决策树模型时,我们首先对空气质量数据进行了详细的特征选择和标签定义。在这个过程中,我们识别出PM2.5、PM10、SO₂、CO、NO₂、O3等关键的大气污染物浓度数据,并将它们划分为城市空气质量特征数据。这些污染物浓度数据是评估空气质量的重要指标,它们反映了空气中污染物的含量和空气质量状况。
为了构建有效的预测模型,我们还需要对空气质量进行明确的分类。在这里,我们将空气质量分为六个类别:优、良、轻度污染、中度污染、重度污染和严重污染。这些分类标准基于空气质量指数(AQI)或其他相关标准,确保了分类的准确性和一致性。通过将空气质量划分为这些具体的类别,我们能够更准确地描述和预测空气质量状况。
在数据处理过程中,我们注意到日期这一因素虽然可能对空气质量有一定影响,但在本次建模中,我们主要关注的是污染物浓度与空气质量之间的关系,因此选择去掉日期这一特征。这样可以简化模型,使模型更加关注于与空气质量直接相关的因素。
最后,我们将经过处理后的空气质量分类数据作为标签数据,用于训练决策树模型。通过这种方法,我们可以利用历史数据中的污染物浓度信息来预测未来的空气质量状况,为城市空气质量管理和环境保护提供决策支持。。
(2)数据集分割:
对准备好的成都市2022年空气质量数据按照15%的测试集比例划分为训练集和测试集。其中空气质量训练集是为空气质量分类随机森林模型训练服务,测试集是为验证训练的空气质量分类随机森林模型效果。
(3)模型训练:
在构建成都市空气质量分类模型时,我们采用了随机森林算法,这是一种基于决策树的集成学习技术,通过组合多个决策树的预测结果来提高分类的准确性和稳定性。我们利用sklearn库中的RandomForestClassifier()函数来实现随机森林模型,并使用成都市的空气质量训练集对该模型进行训练。
随机森林算法的核心思想是在构建每棵决策树时,随机选择数据集中的一部分特征和样本子集,以减少决策树之间的相关性,并增加模型的泛化能力。通过这种方式,随机森林能够捕获到数据中的复杂结构和模式,从而更准确地预测空气质量类别。
一旦模型训练完成,我们使用成都市的空气质量测试集来评估其性能。测试集是与训练集独立的数据集,用于模拟模型在实际应用中面对的新数据。通过将测试集数据输入到已经训练好的随机森林模型中,我们可以得到模型对测试集数据的预测结果。
接着,我们计算了模型在测试集上的准确度,即模型预测正确的样本数占总样本数的比例。结果显示,测试集上的准确度为0.93,这意味着模型在预测空气质量类别时,有93%的样本被正确分类。这一结果非常令人鼓舞,因为它表明模型在未见过的数据上具有良好的泛化能力。
从准确度的角度来看,该空气质量分类随机森林模型表现优异。准确度超过93%是一个相对较高的分值,说明模型在大多数情况下都能做出正确的预测。这一结果验证了随机森林算法在空气质量分类任务中的有效性,并证明了该模型能够准确地区分不同的空气质量类别。
因此,从准确度的角度来看,我们可以判断该空气质量分类随机森林模型是一个较好的模型。它不仅能够有效地拟合训练数据,而且在新数据上也具有良好的泛化能力。这为成都市的空气质量监测和预测提供了一个可靠的工具,有助于我们更好地了解和管理空气质量状况。
空气质量分类随机森林模型混淆矩阵热力图分析
通过空气质量训练集数据训练生成的空气质量分类随机森林模型混淆矩阵热力图如下图

从空气质量分类随机森林模型的混淆矩阵热力图得出的结论来看,我们可以详细分析模型在成都市空气质量测试集上的性能:
(1) 对于空气质量为优的样本,测试集中有20条,其中仅有1条出现了误判,说明模型在识别“优”这一类别时准确率较高,误判率较低。
(2) 空气质量为轻度污染的样本共有24条,其中2条出现了误判,这表明模型在区分轻度污染与其他类别时存在一定的困难,但整体准确率依然较高。
(3) 对于空气质量为良的样本,测试集中有6条,其中1条被误判,这表明模型在识别“良”这一类别时也表现出较好的性能,但仍有改进空间。
(4) 在空气质量为中度污染的样本中,测试集仅有1条,并且该样本没有被误判,说明模型在识别中度污染这一类别时非常准确。
(5) 空气质量为重度污染的样本有3条,并且全部被正确分类,没有误判现象,这进一步证明了模型在识别较为严重的污染类别时的可靠性。
(6) 在空气质量为严重污染的样本中,尽管测试集只有1条,但也出现了1条误判,这可能是由于样本量过少或数据分布不均匀导致的,需要更多的数据来验证模型在该类别上的性能。
(7) 从整体上看,空气质量分类随机森林模型在测试集上的表现相当出色,仅出现了1条误判现象,这充分说明了模型在空气质量分类任务上的有效性。
总结来说,空气质量分类随机森林模型在成都市空气质量测试集上展现出了较高的分类准确率,特别是在识别中度污染和重度污染等较为严重的类别时表现优异。然而,在识别轻度污染和严重污染时,模型仍存在一定的误判率,这提示我们在未来可以进一步优化模型,提高其在这些类别上的分类性能。
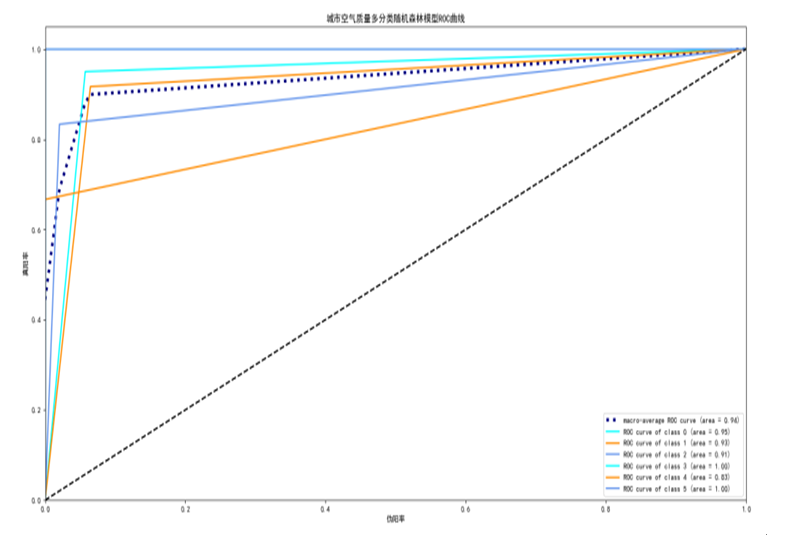
空气质量分类随机森林模型ROC曲线分析
通过空气质量训练集数据训练生成的空气质量分类随机森林模型ROC曲线图如下图

首先,AUC值(Area Under the Curve)是ROC曲线(Receiver Operating Characteristic Curve)下与坐标轴围成的面积,用于量化分类器的性能。AUC值越接近1,说明分类器的性能越好,能够更准确地区分正负样本。
空气质量为优的AUC值是1,表示模型在此类别上的分类性能达到最佳,能够完全区分出“优”的样本。
空气质量为良的AUC值也是1,说明模型在识别“良”的样本时同样表现卓越。
空气质量为轻度污染的AUC值是0.9,虽然略低于前两个类别,但仍然非常接近1,表明模型在区分轻度污染样本时也有很好的性能。
空气质量为中度污染的AUC值同样是0.9,这意味着模型在识别中度污染样本时也能保持较高的准确率。
空气质量为重度污染和严重污染的AUC值均为1,显示了模型在这两个严重污染类别上的出色分类能力。
最后,本模型的平均AUC值为0.93,这是一个非常高的数值,表明空气质量分类随机森林模型在整体上具有很好的分类性能。这证明了通过训练得到的分类器能够很好地适应成都市的空气质量数据,并在不同类别的空气质量预测中均取得了令人满意的结果。
综上所述,空气质量分类随机森林模型在ROC曲线和AUC值的评估下,展现了优秀的分类能力,证明了我们训练得到的模型效果俱佳。
研究背景
近年来,我国的大气环境呈现多样化的状态,出现烟煤型污染与氧化性污染共同存在、局部地区污染和大片区域污染等各种情况叠加的现象,发生了不同污染物相互之间融合反应生成新污染的情况[1]。现如今主要以雾霾天气为代表的复合型污染严重的影响人们的身体健康,人们对城市的光化学烟雾引起的大气污染特别的关注。国家对大气污染也特别重视,将每个城市的空气质量纳入城市综合评比项,并发布各个城市对空气质量至少日报的政策。2021年习主席强调将减少碳排放、提高空气质量作为环境治理的主要任务。如何精准预判空气质量,对污染区域进行专项治理是环境治理部门迫切关注的问题[2]。基于此大背景下,以气象部门检测的大气污染物的含量为依据,建立空气质量的预测模型,实现对城市区域的空气质量提前预判,从而提高空气质量的气象服务,协助环境部门对研判污染物的排放以及空气质量变化情况都有重要的决策在指导,因此本文选择基于随机森林算法的空气质量预测作为研究课题。
研究目的意义
随着社会经济的发展,促进人们的生活水平逐渐提高,人们对生活环境的空气质量情况也逐渐的关注起来,空气质量的好坏直接与人们的出行也息息相关,遇到空气质量差尤其出现雾霾天气,对于计划出行的人们影响非常大,另外良好的空气质量有益于人们的身体健康,因此上至国家政府下至人民群众对与空气质量情况格外关注,由此空气中污染物等信息数据为样本,随机森林对城市空气质量进行预测有着重要的研究价值。
(1)人们提前掌握空气质量情况,可以根据需要合理的安排自己的出行计划,防止因雾霾天气等原因造成出行计划搁置,同时在良好的空气质量环境中出行,能够保护自身的健康,减少各种疾病的发病率,同时可时刻提醒人们,保护环境,减少污染从自我做起。
(2)大气污染对环境有很大的危害,而环境是社会经济发展的前提,因为一些污染环境的经济发展结构和模式最终会产生不良的社会效应,对于社会经济可持续发生起到阻碍作用,因此提前掌握空气质量情况,对于污染性企业的关停限产工作有着指导意义,
(3)空气质量预测对于环保部门,通过提前弄清楚空气污染情况,采取有效的措施遏制污染物,提高空气质量,同时也相应国家政策,坚持对城市的空气质量每日进行预报。
国内外研究现状
我国经济的飞速发展,导致大气污染的问题越发严重,空气质量严重下降,影响人们的身心健康,国家对于空气质量分析研究工作格外重视,许多专家就空气质量的预测分析进行了专门的研究。2019年,夏润,张晓龙通过改进集成学习算法对空气质量进行预测,他们研究的核心是改进OPGBoost算法,为了能够得到更多有效的空气质量相关数据信息,采用Boruta算法对空气质量数据特征进行筛选,最后通过创建OPGBoost组合模型,对空气质量和PM2.5的浓度进行预测,通过实验数据的验证,发展该OPGBoost组合模型的准确性和实用性都是非常强的[3]。张旭通过神经网络算法对空气质量进行预测,他们为了提高对PM2.5等污染物浓度预测度,除了考虑其他污染物得浓度外,将气象因素也考虑进来,并且通过BP神经网络以及深度置信网络建立PM2.5的预测模型。另外为了对小时数据的PM2.5的浓度进行预测,由于小时数据非常庞大,通过建立DBN-SVR预测模型来预测[4]。张晗主要对基于LSTM神经网络实现了空气污染监测预报系统,他指出为了提前了解空气污染情况,指定合理的污染遏制措施,建立空气污染监测预报系统很有必要,他主要依据空气污染和气象数据的时间特点,从时间角度建立他们的关联性,构建LSTM神经网络的空气质量预测模型[5]。
2020年,荆海航等人基于时空数据建立空气质量预测模型,她重点分析空气质量的时空影响因素,利用空间估值划分的方法,获取与该空间区域相关的其他区域的空气质量因素信息,建立关联关系,基于ASTPN模型和ARIMA模型方法,构建空气质量预测模型,对每天24小时的空气质量情况进行预测[6]。刘星宇使用机器学习方法进行空气质量分析和预测,同样深入讨论污染物浓度和气象因素之间的关系,基于ARIMA-SVM模型对空气中的PM2.5的浓进行预测,为了得到高质量的气象因素与污染物浓度的相关数据,他采用K-means聚类算法对数据中的异常值进行处理,其重要是将污染物浓度作为标签,通过聚类中心将气象因素进行聚类,对于异常的气象因素数据分类删除[7]。
2021年,门瑞基于多维特征深度融合的技术对空气质量预测方面的内容进行研究,他依据国家环境监测中心全球预报系统的数据,主要从空间、时间、时空等角度来研究与空气质量有关的因子,基于多空间、时间等相互影响的思想达到降低预测偏差的目的,使得空气质量的预测结果更加贴近实际[8]。祁柏林,郭昆鹏,杨彬等人基于GCN-LSTM技术对空气质量预测进行研究,他们先通过GCN网络分析各个空间检测点的之间的空间关系,接着通过LSTM来得到空间检测的时间特征,最后通过线性回归的方法将得到的空间和时间特征相结合来预测空气质量[9]。通过实验数据验证表明,这种空间和时间结合的方法建立LSTM空气质量预测模型比单一的LSTM空气质量预测模型效果要好很多。王旭坪,于秀丽等人基于集成学习策略方法,主要对化工园区大气污染影响预测进行研究,他们通过对比各种机器学习的预测模型,发现将各种机器学习方法结合得到的化工园区大气污染影响预测模型要比单一的预测模型要好,无论是从模型精度还是从模型的泛化性方面都较为优秀,通过建园区大气污染影响预测模型分析发现,在相同的园区,不同的企业对污染物以及不同的排放口对空气的污染程度也是不同,因此政府可根据大气污染影响预测针对不同的企业进行因地制宜,建立合理的污染管控制度[10]。
国外,工业的发展使得全球的大气污染更加严重,空气质量问题也是全球关注的问题,许多外国学者就空气质量相关工作做了研究。2019年,Esatbeyoglu Enes,Sass Andreas等人基于移动测量数据对空气质量进行预测,本次实验它们通过车辆安装测量技术,对移动路线对应的空气中的NO2浓度等数据进行测量,将测试的NO2浓度等数据作为影响空气质量的因素,进行预测空气质量[11]。Vairo T.,Lecca M.,Trovatore E.等人基于贝叶斯网络对本地的空气质量建模预测,提前预报空气质量,其预测的目标是根据特定区域停滞的污染物情况进行预测空气质量,他们选择意大利的热那亚的空气污染物的相关数据为研究对象[12]。K Srinivasa Rao,G. Lavanya Devi,N. Ramesh]等人采用LSTM递归神经网络技术对维沙卡帕特南的空气质量进行预测,他们通过提取维沙卡帕特南的空气中的NO2浓度等数据,分析不同时间空气中NO2浓度、PM2.5等数据走势,并建立模型预测空气质量[13。Afsaneh Ghasemi,Jamil Amanollahi等人对空气质量预报ANFIS模型和选择方法集成课题进行研究,他们通过分析指出与空气质量相关的因子主要以污染物的浓度以及区域的相对湿度、温度、降水、压力等气象因素也有一定的关系,因此将这些数据作为因子,采用FS方法和ANFIS模型进行空气质量的预测[14]。
2020年,Chadha A.,Gupta S.等人基于机器学习算法对空气质量预测,他们指出空气污染不但对人们的健康有一定的威胁,而且对环境有一定的危害,因此对于空气质量的预测很有必要,他们以印度城市的空气质量指数为预测对象,采用时间序列模型预测造成空气污染的每个污染物的浓度,然后基于这些污染物的浓度,采用回归模型预测空气质量指数[15]。Saini Jagriti,Dutta Maitreyee等人基于SGD优化器对室内的空气质量进行预测,他们对印度农村室内空气环境进行调研,发现印度农村室内使用的煤油、木柴、沼气等等都是降低室内空气质量的主要原因,每年死于室内空气质量差的人数有1万人,基于此种情况,他们通过SGD优化器方法对室内的空气质量进行预测,提前预报室内空气质量,有助于印度民众做好防护工作[16]。
研究内容及章节安排
本文以2022年成都市气象部门检测的空气质量数据为研究对象,建立城市空气质量分类随机森林模型对未来空气质量进行预报。其组织结构如下。
第一章绪论,重点分析我国大气污染的现状以及空气质量预报的重要性,对国内外大气污染相关研究情况进行介绍,同时阐述了随机森林算法在其它领域的应用情况,最后得出本文以空气质量预测为研究内容,并对本文结构做了阐述。
第二章重要算法及相关技术介绍,重点阐述了随机森林分类算法以及评估的相关知识。
第三章市空气质量数据准备和清洗,主要围绕城市空气质量数据来源、相关因素确定、采集、城市空气质量数据清洗等内容展开描述。
第四章城市空气质量数据分析,重点叙述了城市空气质量数据相关性分析、城市空气质量数据离散度分析处理以及城市空气质量统计分析等内容。
第五章城市空气质量分类随机森林模型构建,主要介绍了城市空气质量分类随机森林模型从训练、到评估预测的相关过程。
第六章总结与展望,对基于随机森林算法的空气质量预测课题的研究做以总结,对下步该课题延申的内容进行阐述
成都的空气质量数据包含了多个指标,如空气质量等级(以文字形式表示)、PM2.5、PM10、SO2、CO、NO2和O3的浓度值(以字符形式表示,包含单位μg/m³或mg/m³)。为了进行进一步的数据分析或可视化,我们需要对这些数据进行转换。
一、转换步骤:
(1)空气质量等级转换:
空气质量等级包含优、良、轻度污染、中度污染、重度污染、严重污染六个等级。
我们需要将这些等级转换为数字形式,其中“优”对应0,“良”对应1,“轻度污染”对应2,依此类推,直到“严重污染”对应5。
(2)污染物浓度值转换:
对于PM2.5、PM10、SO2、CO、NO2和O3的浓度值,我们需要去掉其单位(μg/m³或mg/m³),并将剩余的字符转换为数字形式。。
(3)数据存储:
转换后的数据将被保存到一个名为“成都空气质量类型数据.xls”的Excel文件中。
这个文件将包含转换后的空气质量等级和污染物浓度值。
二、具体操作:
(1)读取原始数据:
首先,我们需要读取存储成都空气质量数据的原始文件或数据源。
(2)空气质量等级转换:
使用条件语句(如if-else)来实现空气质量等级的转换。遍历数据集中的空气质量等级字段,并根据等级将其转换为对应的数字。
(3)污染物浓度值转换:
使用字符串处理函数(如Python中的str.replace())来去除浓度值中的单位。使用类型转换函数(如Python中的int()或float())将剩余的字符转换为数字。
(4)数据存储:使用数据处理库pandas和Excel写入库openpyxl来创建和写入Excel文件。将转换后的数据存储在“成都空气质量类型数据.xls”文件中,确保文件的格式和列名正确。
城市空气质量数据去重
根据采集的目的值采集2022年全年每日的数据,根据采集结果得到369条数据,通过统计本城市空气质量数据的重复数据共计1条,因此通过df的drop_duplicates()的方法对城市空气质量数据进行去重,将得到的结果存储在文件“成都空气质量去重数据.xls”中。
计算机毕业设计源码网,常年代做计算机专业毕业设计服务、主要包括php、java、asp.net、安卓、微信小程序、人工智能、大数据、数据挖掘、深度学习、爬虫、HTML5响应式网站等,是大学毕业生不可或缺的论文写作参考网站。团队合作,质量保证。值得信赖! Power by DedeCms
COPYRIGHT © 2012-2025 计算机毕业设计源码网(51sjlw.com)版权所有
本站由为毕设源码站提供计算与安全服务.备案号:鲁ICP备2022033926号-2